

共计 2453 个字符,预计需要花费 7 分钟才能阅读完成。
正如我们所说的 Apache Doris 是一个能够处理各种分析工作负载的一体化数据平台,通过实际用例来证明这一点总是令人信服的。这就是为什么我想与您分享这个用户故事。这是关于他们如何利用 Apache Doris 在报告、客户标记和数据湖分析方面的功能并实现高性能。
这家金融科技服务提供商是 Apache Doris 的长期用户。他们有近 10 个生产集群、数百个 Doris 后端节点和数千个 CPU 核心。总数据量接近 1PB。每天,他们有数百个工作流程同时运行,接收近 100 亿条新数据记录,并响应数百万条数据查询。
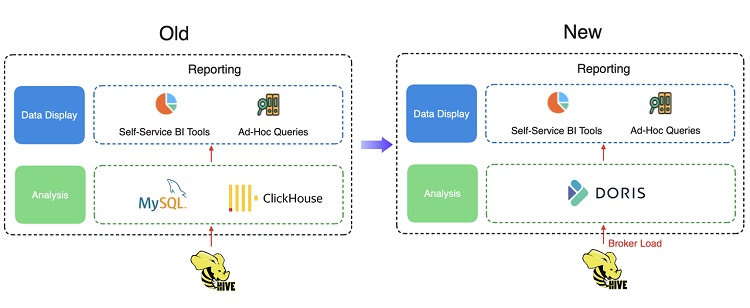
在迁移到 Apache Doris 之前,他们使用 ClickHouse、MySQL 和 Elasticsearch。然后,不断扩大的数据量就会产生摩擦。他们发现 ClickHouse 集群很难横向扩展,因为依赖项太多。至于 MySQL,他们必须在各个 MySQL 实例之间切换,因为一个 MySQL 实例有其局限性,并且不支持跨实例查询。
报告
从 ClickHouse + MySQL 到 Apache Doris
数据报告是他们向客户提供的主要服务之一,并且受到 SLA 的约束。他们过去通过 ClickHouse 和 MySQL 的组合来支持此类服务,但他们发现数据同步持续时间存在显着波动,这使得他们很难满足 SLA 中概述的服务水平。诊断结果显示,由于组件较多,导致数据同步任务的复杂性和不稳定性。为了解决这个问题,他们使用 Apache Doris 作为统一分析引擎来支持数据报告。
性能改进
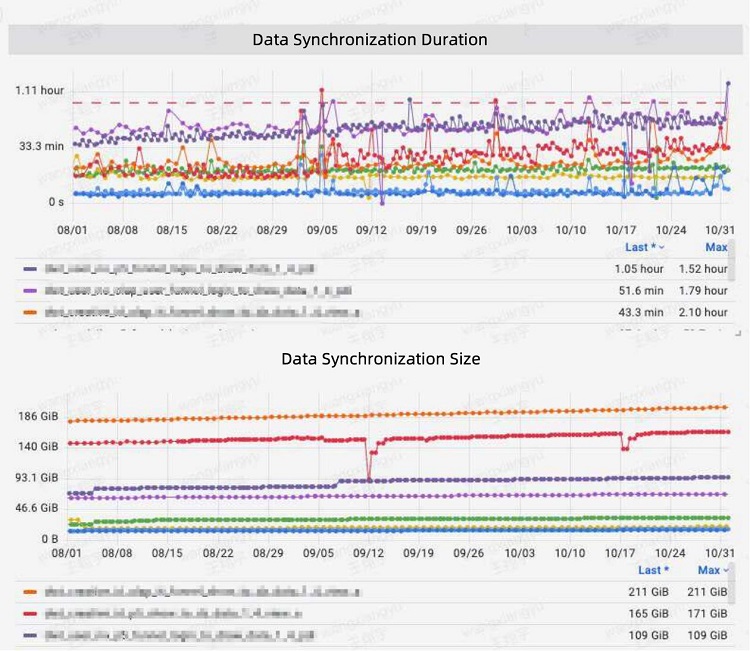
借助 Apache Doris,他们通过 Broker Load 方式摄取数据,并在数据同步性能方面达到 99% 以上的 SLA 合规率。
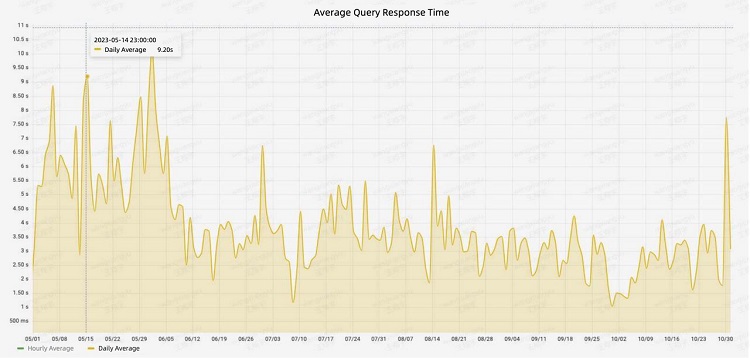
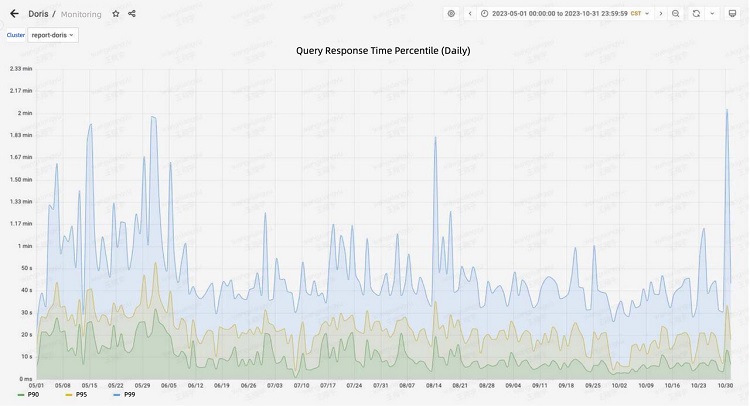
在数据查询方面,基于 Doris 的架构保持平均查询响应时间小于 10 秒,P90 响应时间小于 30 秒。与旧架构相比,速度提高了 50%。
标记
标记是客户分析中的常见操作。您可以根据客户的行为和特征为他们分配标签,以便将他们分组并为每个组制定有针对性的营销策略。
在旧的处理架构中,Elasticsearch 是处理引擎,原始数据被正确地摄取和标记。然后,它将合并为 JSON 文件并导入 Elasticsearch,为分析师和营销人员提供数据服务。在这个过程中,合并的步骤是为了减少更新,减轻 Elasticsearch 的负载,但结果却成了一个麻烦制造者:
任何标签中的任何有问题的数据都可能破坏整个合并操作,从而中断数据服务。
合并操作基于 Spark 和 MapReduce 实现,耗时长达 4 个小时。如此长的时间框架可能会侵犯营销机会并导致看不见的损失。
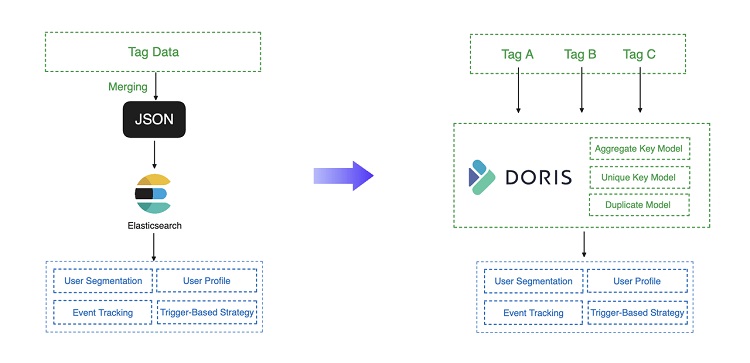
然后 Apache Doris 接管了这个工作。Apache Doris 通过其数据模型来排列标签数据,从而快速、流畅地处理数据。上述合并步骤可以通过聚合密钥模型来完成,该模型在数据摄取时根据指定的聚合密钥聚合标签数据。唯一键模型对于部分列更新很方便。同样,您所需要的只是指定唯一密钥。这样可以实现快速灵活的数据更新,并免除您更换整个平板的麻烦。您还可以将详细数据放入重复模型中以加快某些查询的速度。在实践中,用户需要 1 小时才能完成数据摄取,而旧架构需要 4 小时。
在查询性能方面,Doris 配备了成熟的位图索引和针对高并发查询定制的技术,因此在这种情况下,它可以在秒级内完成客户细分,并且面向用户的查询达到 700 以上的 QPS。
数据湖分析
在数据湖场景中,需要处理的数据量往往很大,但每次查询的数据处理量往往各不相同。为了保证海量数据集的快速数据摄取和高查询性能,您需要更多的资源。另一方面,在非高峰时间,您希望缩小集群规模以实现更高效的资源管理。你如何处理这个困境?
Apache Doris 具有一些专为数据湖分析而设计的功能,包括多目录和计算节点。前者可以帮助您避免数据湖分析中数据摄取的麻烦,而后者则可以实现弹性集群扩展。
多目录机制允许您将 Doris 连接到各种外部数据源,这样您就可以将 Doris 作为统一的查询网关,而不必担心将大量数据引入 Doris。
Apache Doris 的计算节点是一个后端角色,专为远程联合查询工作负载(例如数据湖分析中的工作负载)而设计。普通的 Doris 后端节点负责 SQL 查询执行和数据管理,而 Doris 中的计算节点,顾名思义,只执行计算。计算节点是无状态的,使其具有足够的弹性以进行集群扩展。
用户将计算节点引入其集群,并将其与其他组件一起部署在混合配置中。因此,集群会在夜间查询请求较少时自动缩小规模,并在白天进行横向扩展以处理大量查询工作负载。这更加节省资源。
为了更轻松地部署,他们还通过 Skein 优化了 Deploy on Yarn 流程。如下所示,他们在 YAML 文件中定义 Compute 节点的数量和所需的资源,然后将安装文件、配置文件和启动脚本打包到分布式文件系统中。通过这种方式,他们可以使用一行简单的代码在几分钟内启动或停止超过 100 个节点的整个集群。
 文章来源:https://www.toymoban.com/diary/system/657.html
文章来源:https://www.toymoban.com/diary/system/657.html
结论
对于数据报告和客户标记,Apache Doris 简化了数据摄取和合并步骤,并基于其自身的设计和功能提供了高查询性能。对于数据湖分析,用户通过使用计算节点弹性扩展集群来提高资源效率。在使用 Apache Doris 的过程中,他们还开发了一种数据摄取任务优先级机制,并将其贡献给 Doris 项目。促进其用例的举动最终将使整个开源社区受益。这是开源产品因用户参与而蓬勃发展的一个很好的例子。 文章来源地址 https://www.toymoban.com/diary/system/657.html
到此这篇关于 Apache Doris 加速数据报告、标记和数据湖分析的文章就介绍到这了, 更多相关内容可以在右上角搜索或继续浏览下面的相关文章,希望大家以后多多支持 TOY 模板网!
原文地址:https://www.toymoban.com/diary/system/657.html
如若转载,请注明出处:如若内容造成侵权 / 违法违规 / 事实不符,请联系站长进行投诉反馈,一经查实,立即删除!





